

Et si un moteur de recherche pouvait servir les internautes sans invisibiliser ceux qui créent les contenus qu’ils consultent ? C’est le pari d’Ibou, moteur de recherche conversationnel français cofondé par Sylvain Peyronnet et Guillaume Pitel via leur société Babbar. Après six ans à construire l’une des plus importantes infrastructures d’indexation web d’Europe, le projet franchit une étape décisive : la bêta publique d’Ibou Explorer, avec Xavier Niel comme nouvel investisseur. Rencontre.
Pouvez-vous nous présenter Ibou ? Pourquoi avoir décidé de lancer ce projet ?
Sylvain Peyronnet : Ibou, c’est un moteur de recherche conversationnel. L’ambition du projet est de proposer une solution conçue et opérée en France. Si on a décidé de se lancer, c’est parce qu’on a fait un constat : le web tel qu’il est n’est pas le web tel qu’on le voudrait et ce, parce que les algorithmes de recherche et de recommandation sont une forme de pouvoir. Ils influencent la façon dont les gens s’informent et pensent. Ce pouvoir algorithmique est d’autant plus redoutable qu’il est invisible. Les gens pensent chercher librement, alors qu’on leur montre ce qui maximise le temps passé. Ils pensent s’informer, alors qu’on les enferme dans des boucles de confirmation.
Face à ça, on a un devoir : créer des algorithmes vertueux. Ibou est la matérialisation de ce devoir.
Le web a besoin d’un moteur qui serve à la fois les internautes et ceux qui créent les contenus qu’ils consultent. Là où les moteurs dominants ont progressivement relégué beaucoup de sites au second plan, on fait le choix inverse : mettre en valeur les sources, garantir le pluralisme de l’information et respecter la volonté des éditeurs.
Techniquement parlant, qu’est-ce qu’il y a sous le capot ?
Guillaume Pitel : Le socle, c’est l’infrastructure de Babbar, qu’on construit depuis 2019. On a deux crawlers :
- Barkrowler : notre crawler historique qui traite entre 2 et 3 milliards de pages par jour,
- IbouBot : dédié au moteur, qui figure déjà parmi les tout premiers bots européens dans la catégorie moteur de recherche selon Cloudflare Radar.
Notre index évolue en permanence. Nous avons crawlé au total 3 300 milliards de pages depuis sa création, mais l’index actif contient aujourd’hui plus de 500 milliards de pages web, avec un graphe de plus de 7 000 milliards de liens. C’est l’un des plus gros index en dehors des moteurs majeurs. Nous avons d’ailleurs récemment réduit sa taille en rehaussant nos exigences de qualité sur ce qu’on crawle et ce qu’on conserve. Il fut un temps où notre graphe comptait 15 000 milliards de liens.
Côté ranking, on utilise plusieurs couches avec différents niveaux de coûts. En fondation, on s’appuie sur des métriques de graphe propriétaires, de la proximité sémantique extrêmement optimisée et des critères de qualité que nous affinons en permanence.
Au sommet, notre algorithme propriétaire Mimesis peaufine la sélection des passages pertinents. L’idée de fond, c’est qu’un moteur classique a besoin de milliards de clics utilisateurs pour entraîner son classement par machine learning. C’était le « moat » historique de Google. Les LLM ont fait tomber cette barrière. On utilise une approche LLM-as-a-Judge : des modèles de langage annotent les paires requête/document sur la légitimité, l’expertise, la complétude, le style et les signaux suspects. Ces annotations nous permettent de valider nos choix algorithmiques et d’entraîner Mimesis à apprendre des règles contextuelles sur des centaines de millions de documents. On traite environ 100 signaux par document : autorité du site, diversité des backlinks, confiance, expertise E-E-A-T, correspondance sémantique (à la fois lexicale et neuronale), qualité éditoriale et potentiel d’engagement. Le tout repose sur notre recherche hybride dense-sparse, qui combine la correspondance lexicale exacte et la compréhension sémantique profonde.
Ce qui est fondamental, c’est qu’on ne dépend de personne pour le cœur du moteur : index, crawl et ranking sont propriétaires. Pas d’API tierce et donc, aucune dépendance structurelle.
La bêta d’Ibou Explorer est désormais accessible à tous. Qu’est-ce qui le différencie d’un Google Discover ?
S.P : Google Discover optimise l’engagement. Le résultat, on le connaît : du clickbait, des contenus IA générés en masse, de la désinformation. Reporters Sans Frontières a d’ailleurs interpellé Google l’année dernière en identifiant des milliers de faux sites d’actualités IA poussés par Discover. Google a même dû publier sa première mise à jour spécifique à Discover en février 2026, en reconnaissant explicitement le problème du clickbait.
Ibou Explorer fait un choix radicalement différent. On optimise pour la qualité éditoriale et le pluralisme plutôt que pour l’engagement pur. Notre pipeline filtre d’abord les sites par un seuil de qualité minimum (performance technique, absence de pollution publicitaire, contenus travaillés), puis chaque article passe par un scoring multi-dimensionnel : qualité rédactionnelle, score de risque sur les sujets sensibles, détection de contenu IA basse qualité, expertise de la source.
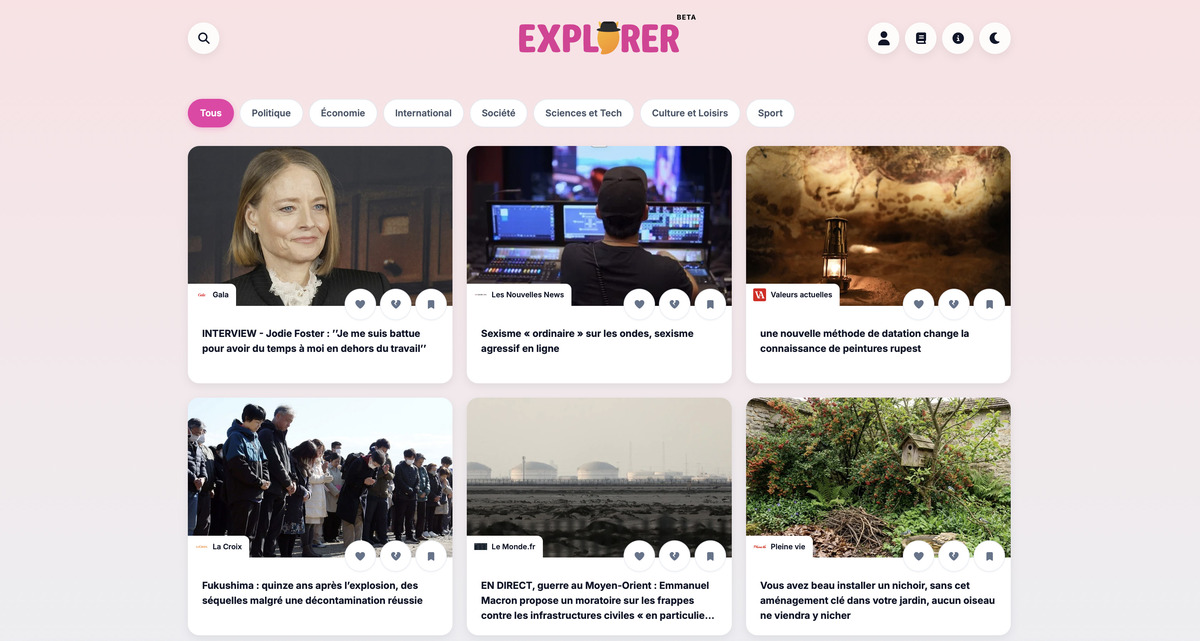
Autre différence majeure : on intègre un mécanisme actif de diversité pour casser les bulles de filtre. Les utilisateurs de la bêta ont déjà pu le constater, c’est un sujet sur lequel on travaille énormément. Enfin, et c’est fondamental : Ibou a pour mission d’envoyer les gens vers les sources, pour que le web de qualité perdure.
Comment votre algorithme distingue un article de qualité d’un article médiocre ? Les articles générés par IA sont-ils pénalisés ?
G.P : On évalue chaque contenu sur plusieurs axes simultanément. D’abord un score de qualité éditoriale : la rédaction est-elle soignée, l’article est-il bien structuré, riche en information, sourcé ? Ensuite un score E-E-A-T agrégé (expertise, autorité, accessibilité, transparence). Pour donner un ordre d’idée : un article bien documenté et expert atteindra 80 %, un article Substack typique se situera autour de 64 % et un article médiocre autour de 52 %.
On ajoute à cela un score de risque inspiré du YMYL (Your Money, Your Life) : les articles qui traitent de santé ou de finances doivent franchir un seuil beaucoup plus élevé. Un article approximatif sur un remède médical ne passera pas le filtre, même s’il est bien rédigé.
Sur l’IA, notre position est nuancée. On ne pénalise pas un article simplement parce qu’il a été produit avec l’aide d’une IA. Ce qu’on pénalise, c’est le contenu basse qualité, avec peu ou pas de valeur ajoutée informationnelle. Le « slop » comme on dit dans le métier. Notre détection distingue les contenus véritablement travaillés du remplissage généré en masse. Un journaliste qui utilise un LLM pour améliorer sa prose tout en apportant son expertise, son investigation, ses sources, ça reste un contenu de qualité. Une ferme de contenus qui génère 500 articles par jour sans aucune valeur ajoutée, non.
Un éditeur ou un média doit-il faire une démarche particulière pour apparaître dans Ibou Explorer ?
S.P : L’insertion est principalement gérée par nos process. Notre crawler explore le web en continu et indexe les sites qui remplissent nos critères de qualité. Si un site publie du contenu de qualité, il a vocation à apparaître dans Explorer sans aucune démarche de sa part.
Et on tient à souligner un point essentiel : on respecte scrupuleusement les instructions des fichiers robots.txt. Si un éditeur ne veut pas être indexé par Ibou, on le respecte. Et s’il souhaite être exploré différemment, on est à l’écoute de ses besoins. C’est écrit dans notre manifeste et c’est une règle non négociable.
Comment apparaître dans Ibou Explorer ?
Ibou Explorer indexe automatiquement les sites qui remplissent ses critères de qualité, aucune démarche n’est nécessaire. Quelques prérequis techniques de base sont cependant attendus :
- Bonnes performances du site et des pages
- Sitemap ou flux RSS bien formés
- UX acceptable, sans surcharge publicitaire
- Contenus travaillés, sans remplissage généré en masse
Les éditeurs qui ne souhaitent pas être indexés peuvent le signaler via leur fichier robots.txt.
Google utilise l’IA pour générer des résumés directement dans les résultats. Chez Ibou, quel est le rôle de l’IA et quelle est votre philosophie ?
G.P : Les AI Overviews de Google illustrent parfaitement le problème systémique qu’on dénonce. Google aspire le contenu des éditeurs, le synthétise dans ses propres résultats, et l’utilisateur n’a plus besoin de visiter la source. Les chiffres sont parlants : le taux de clics a chuté de près de moitié sur les requêtes avec AI Overviews, et seulement 1 % des utilisateurs cliquent sur les liens cités dans ces résumés. Pour les éditeurs, c’est dévastateur.
Chez Ibou, l’IA est partout dans notre pipeline, du crawl au ranking en passant par l’évaluation de la qualité, mais elle est au service d’une philosophie opposée. On l’utilise pour évaluer la pertinence, croiser les sources, détecter le spam et la désinformation. Ce qu’on ne fait pas, c’est s’en servir pour rendre le créateur invisible.
Quand notre moteur conversationnel sera complet, l’utilisateur aura bien une synthèse fiable à partir de sources multiples. Mais avec attribution systématique et renvoi de trafic réel vers les éditeurs. C’est un équilibre à trouver : les gens ne cherchent pas des pages web, ils cherchent des réponses. Mais si le moteur ne renvoie pas de visibilité aux producteurs de contenu, il tarit sa propre source. On intègre aussi un système d’arbitrage IA conçu pour vérifier, croiser et qualifier la fiabilité des réponses générées, afin de lutter contre les hallucinations.
Comment Ibou va-t-il générer des revenus ? Quel business model est envisagé ?
S.P : La monétisation globale chez Ibou doit être cohérente avec la vision. Si on trahit la mission pour faire du chiffre, autant ne pas la lancer. Pour l’instant, seul Ibou Explorer est actif, et il met déjà en avant des contenus de façon contextuelle, selon les centres d’intérêt de l’utilisateur, dans une logique d’apport de trafic où les éditeurs y gagnent aussi.
Ibou Search intégrera de la publicité contextuelle et de l’affiliation. On fait le choix délibéré de prioriser la contextualisation et la qualité comme signaux d’arbitrage. Concrètement, ça veut dire un revenu par utilisateur potentiellement moindre, mais un service qui ne trahit pas la mission.
Au-delà du moteur grand public, notre index web indépendant est une brique critique pour tout l’écosystème IA du continent. Les LLM, les chatbots, les agents ont besoin d’accéder au web. Si cette couche d’accès reste américaine, la souveraineté sur les modèles eux-mêmes est un leurre. Nous avons vocation à fournir cet index à d’autres acteurs, c’est un levier de revenus important.
Dans votre manifeste, vous écrivez vouloir « un Internet qui reste public, ouvert, et qui respecte ceux qui le font vivre ». Qu’est-ce que ça signifie concrètement ?
G.P : Concrètement, « public et ouvert », ça veut dire qu’on s’oppose à l’enfermement des contenus derrière des murs opaques, tout en laissant les créateurs maîtres de leurs choix de diffusion. On ne force rien. On crawle dans le respect des infrastructures, à des vitesses adaptées pour ne pas nuire aux serveurs, il faut que ce soit compris par les webmasters qui doivent nous ouvrir volontairement leurs portes, on ne veut pas faire comme certains concurrents qui annoncent publiquement crawler de manière dissimulée. On contribue aussi à un Internet sobre : notre objectif est de trouver un équilibre et d’utiliser le minimum de ressources pour obtenir la donnée.
« Respecter ceux qui le font vivre », c’est reconnaître que l’information de qualité a un coût de production. Journalistes, chercheurs, blogueurs, photographes, développeurs, tous ces gens produisent le contenu que le web valorise. La tendance sur les modèles actuels des moteurs les invisibilise progressivement. Nous, on s’engage sur l’attribution systématique, le renvoi de trafic réel, la transparence sur l’utilisation des contenus. Nos méthodes de crawl, d’indexation et de présentation des résultats feront l’objet d’une information sincère et accessible. On publie déjà régulièrement sur notre Substack le détail de nos choix algorithmiques. C’est à notre connaissance assez rare dans l’industrie.
Ce n’est pas un slogan marketing, ce manifeste est un engagement public et vérifiable.
D’autres acteurs européens ont déjà tenté de concurrencer Google (Qwant, Lilo…). Qu’est-ce qui distingue fondamentalement Ibou ?
S.P : Je connais très bien l’histoire de ces projets, puisque j’ai participé plusieurs années à l’un d’entre eux (ndlr : Sylvain Peyronnet était Chief Science Officer (CSO) de Qwant, avant de cofonder Babbar en 2019). Toutes les tentatives de moteur en France et plus largement en Europe ont eu de lourdes dépendances à Bing (souvent à plus de 60 %). C’est la démonstration que sans maîtrise de son infrastructure, on est à la merci des décisions d’un tiers américain.
Ibou est fondamentalement différent sur trois points. D’abord, notre infrastructure existe déjà et elle est à nous : 3 300 milliards de documents indexés, deux crawlers opérationnels, des métriques propriétaires construites depuis 2019. Ce n’est pas une promesse, c’est un actif que six ans de travail ont produit. Ensuite, la fenêtre technologique s’est ouverte : les LLM permettent aujourd’hui de produire un ranking compétitif sans les décennies de données de clics qui étaient nécessaires auparavant.
Nous ne sommes pas le « nouveau Qwant » ni le « Google français ». On est Ibou, avec notre propre vision et notre propre modèle. On veut montrer qu’on peut réussir un projet tech ambitieux porté par des valeurs, depuis la France.
Xavier Niel vient de rejoindre le projet. Quelles sont les prochaines grandes étapes ? Avez-vous une date de déploiement en tête ?
G.P : L’entrée de Xavier Niel aux côtés de nos investisseurs historiques ; Go Capital, Bpifrance et Normandie Participations donne les moyens de passer à l’étape suivante, avec le soutien complémentaire d’acteurs régionaux comme l’AD Normandie. Ce qui nous a convaincus dans cette rencontre, c’est le partage d’une conviction commune : qu’il est possible de construire un moteur de recherche qui respecte à la fois les utilisateurs et les créateurs de contenu.
La roadmap est claire. Explorer est déjà en bêta publique et les retours nous permettent d’améliorer le produit en continu. Ensuite viendront la recherche d’images, puis le moteur de recherche conversationnel complet. Notre objectif est de livrer ce moteur complet d’ici la fin de l’année 2026.
S.P : J’ajouterais un point. L’adhésion la plus durable ne vient pas des discours, elle vient de ce qu’on livre. Un crawler qui marche. Un index qui grossit. Un produit qui donne de bons résultats. Des éditeurs qui voient leur trafic. Montrer, pas promettre. C’est la seule stratégie qui tiendra dans le temps. Et c’est exactement ce qu’on fait : Explorer est là, il fonctionne, les gens peuvent l’essayer dès maintenant juste par ici !

Sylvain Peyronnet, Co‑fondateur et CEO, Babbar et Ibou
Sylvain Peyronnet est expert en SEO, en algorithmie et en science des données depuis plus de 20 ans, et ancien professeur universitaire. Co-fondateur de Babbar, il conçoit des outils d’analyse avancée pour le référencement, en s’appuyant sur une approche scientifique et technique du web. Il est également le co-fondateur et CEO d’Ibou, un moteur de recherche conversationnel qui place le respect des utilisateurs et des créateurs de contenu au cœur de son modèle.

Guillaume Pitel, Co-fondateur et CTO, Babbar et Ibou
Ingénieur EPITA, docteur en informatique et linguistique computationnelle, Guillaume Pitel fonde eXenSa en 2011, où il développe des technologies de traitement de données textuelles et de machine learning à grande échelle. Il cofonde Babbar en 2019 et y bâtit le crawler et l’infrastructure d’indexation qui constituent le socle technologique d’Ibou, le moteur de recherche conversationnel français.